
Espiar nuestra red
Para delimitar quien puede usar nuestra red necesitaremos espiarnos a nosotros mismos, buscando garantizar la disponibilidad de la red (localizaremos enlaces saturados) y detectar ataques en curso.
Vamos a procesar el trafico de nuestra red mediante dos tipos de técnicas:
- La monitorización del tráfico. Trabaja a alto nivel: se limita a tomar medidas agregadas, los llamados contadores.
- Resulta fácil de activar en toda la red dado que son los propios equipos los que facilitan esta información sobre sus interfaces.
- Genera relativamente poca información para transmitir y procesar.
- Es suficiente para conocer la disponibilidad de la red o el tipo de tráfico que transita.
- El análisis del tráfico. Trabaja a bajo nivel: captura todos los paquetes que transitan por una interfaz (los conocidos sniffer de red). Los paquetes solo son leídos, no interceptados: el paquete contiene su camino. El procesamiento d estos paquetes leídos permite generar medidas agregadas, pero sobre todo interesa analizar las conversaciones entre los equipos, comprobando que se ajustan al comportamiento esperado en el protocolo estándar (analizador de protocolos). Aunque esta información es mucho más rica que los simples contadores, la captura es muy costosa de activar en toda la red, por que se dispara la cantidad de información que hay que transmitir y procesar; por este motivo, solo se utiliza en situaciones concretas que no se pueden abordar con el estudio de contadores como es la detección de ataques.
Como hemos señalado con anterioridad, la monitorización del tráfico es relativamente fácil de activar en una red, porque los equipos suelen estar preparados para facilitarnos la información sobre sus contadores y basta con pregúntales periódicamente. En cambio, la captura de conversaciones es más compleja de activar. Las opciones son:
- Conseguir el control sobre algunos de los extremos de la conexión para poder utilizar alguna de las herramientas que veremos (tcpdump y wireshark).
- Interceptar la conexión misma desde algún equipo de red por donde pasen los paquetes intercambiados. Si este equipo tiene cierta inteligencia, seguramente incorporará funcionalidades avanzadas, como el port mirroring; incluso puede ser un router GNU Linux, con lo que tendremos a nuestro alcance todas las herramientas que veremos para los extremos.
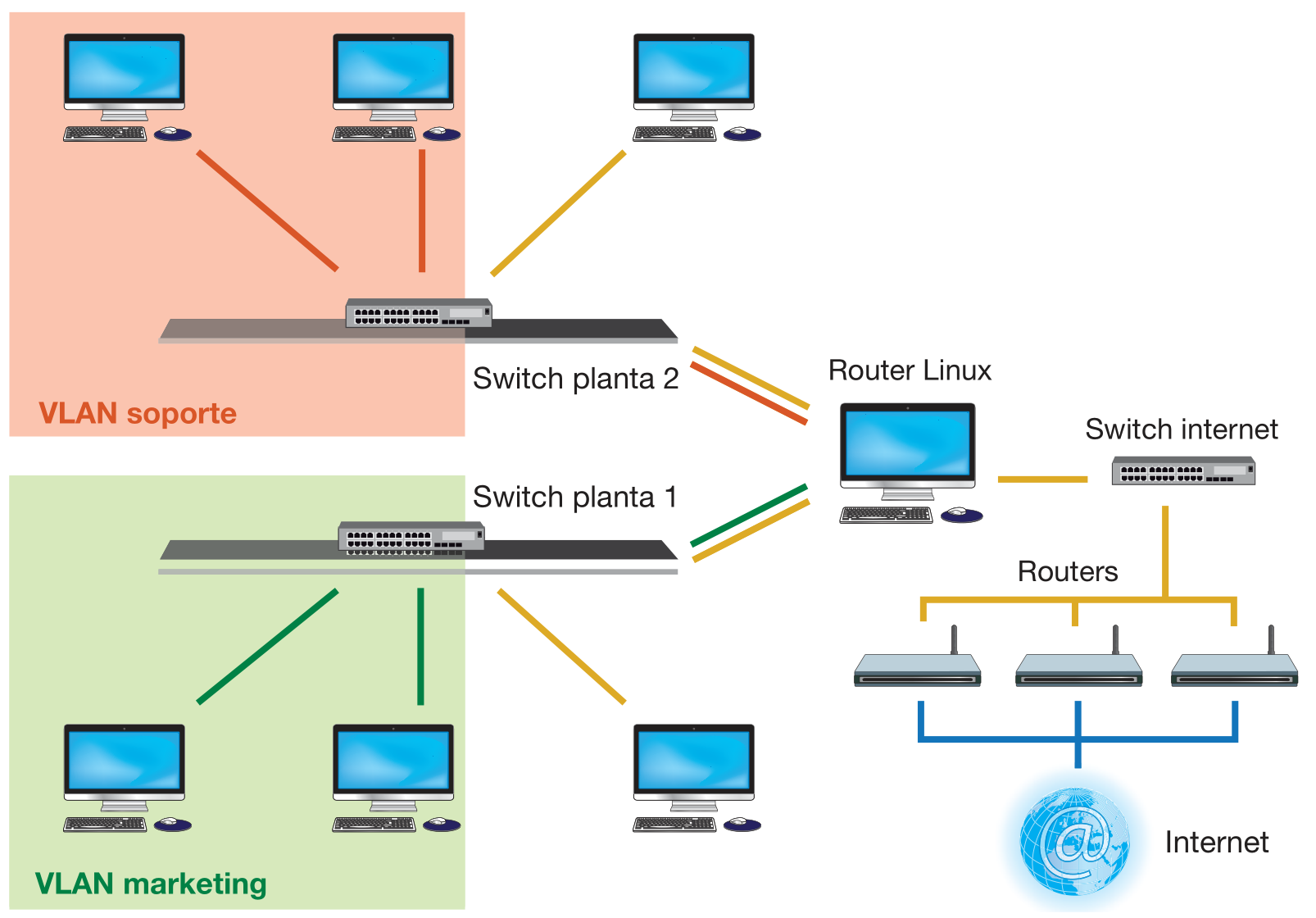 Captura con router GNU Linux
Captura con router GNU Linux
- Como último recurso podríamos conectar de manera temporal un hub en el puerto que queremos vigilar, pero este supone desplazamientos de personal y equipos que no siempre están disponibles.
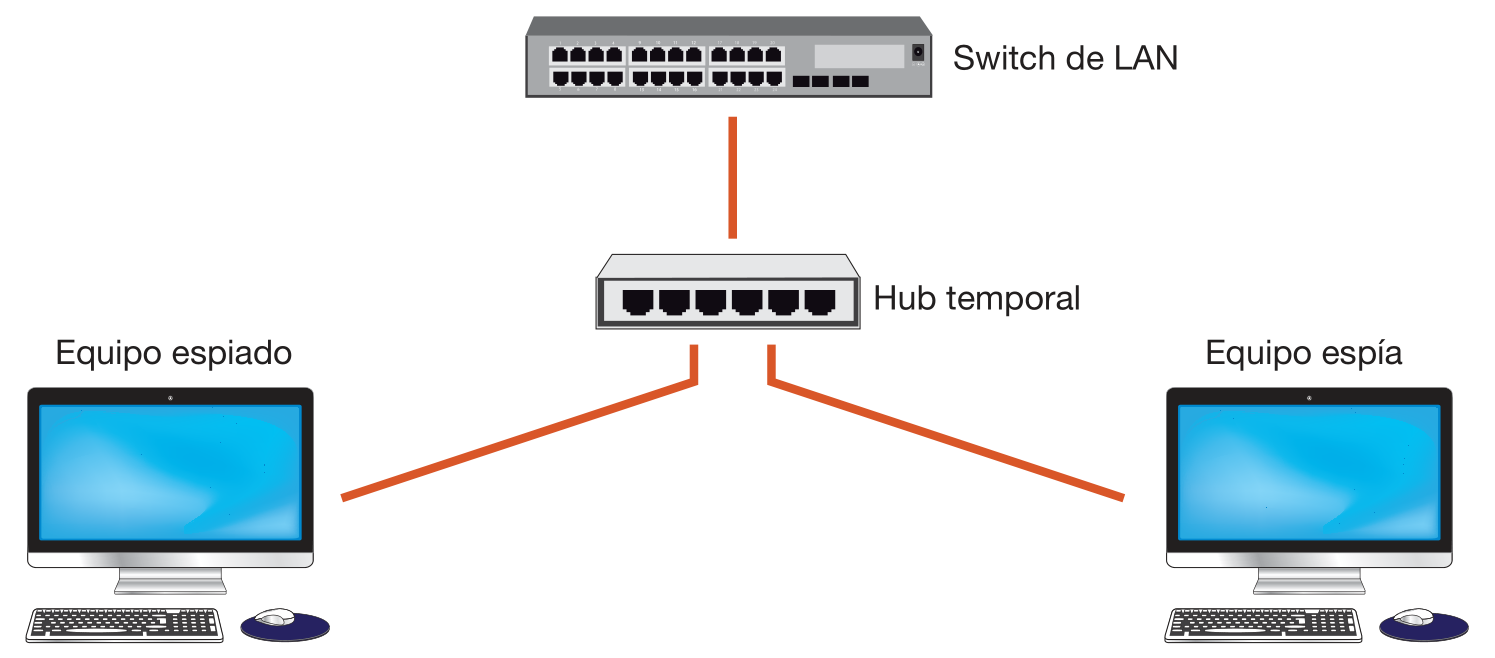 Espionaje utilizando HUB temporal
Espionaje utilizando HUB temporal
Tcpdump
Tcpdump es una herramienta sencilla disponible en GNU Linux que permite hacer un volcado de todo el tráfico que llega a una tarjeta de red. Captura todo el tráfico, no solo el tráfico TCP, como aparece en su nombre. Los paquetes leídos se muestran en pantalla o se pueden almacenar en un fichero del disco para ser tratados posteriormente por esta misma herramienta u otra más avanzada. Se necesitan privilegios para ejecutar, porque necesitamos poner la tarjeta en modo promiscuo para que acepte todos los paquetes, no solo los destinados a su MAC.
WireShark
WireShark es la herramienta más extendida en Windows para realizar capturas de tráfico y analizar los resultados. Es una evolución de una herramienta anterior llamada Ethereal. Para la captura de paquetes utiliza la librería pcap, que también aparece en otros sniffer, como tcpdump. La interfaz de usuario es muy potente, así como el número de protocolos que es capaz de analizar.
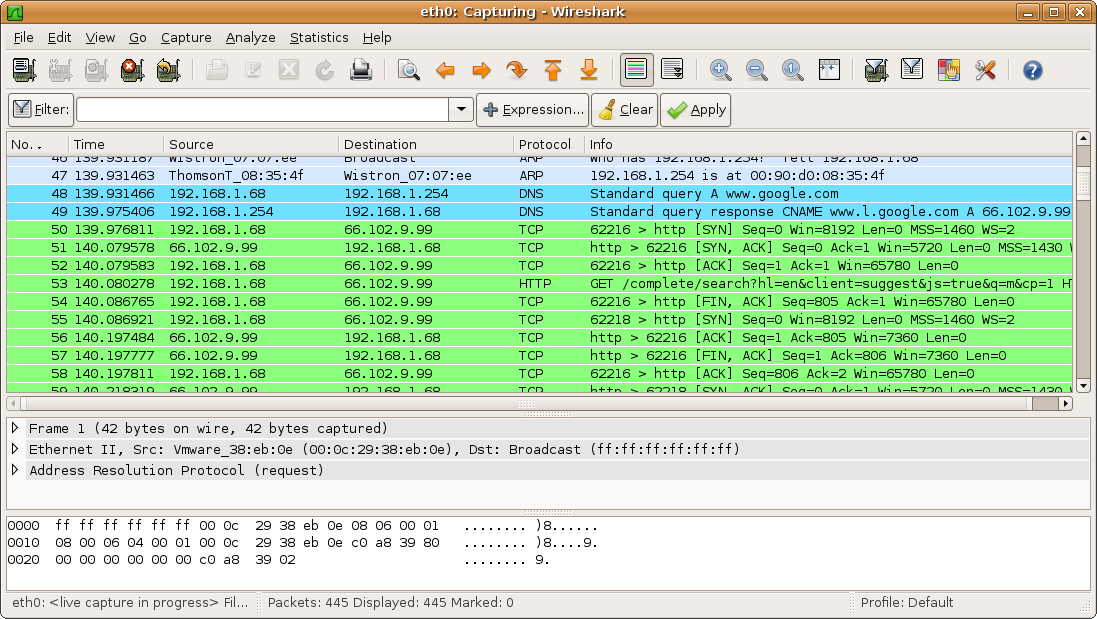 Interfaz de Wireshark
Interfaz de Wireshark
¿Qué es un sniffer? ¿Sabrías poner algún ejemplo?
¿Qué diferencia hay entre Tcpdump y WireShark?
Port Mirroring
Los switch gestionables suelen incorporar esta funcionalidad. Consiste en modificar la configuración del switch para que replique todo el tráfico de un puerto a otro. En el segundo puerto conectaremos el sniffer. El equipo o equipos conectados en el primer puerto funcionan con normalidad y no saben que están siendo espiados.
IDS/IPS
Las herramientas de análisis de tráfico son más o menos sencillas de instalar y configurar; pero la complicación viene a la hora de interpretar los resultados. Para sacar el máximo partido a estas herramientas se necesitan muchos conocimientos de base y una amplia experiencia en protocolos de comunicaciones.
Hay un segundo problema: Aunque dispongamos de personal tan cualificado, no es humanamente posible revisar una a una todas las conversaciones que ocurren a diario en una red normal. Sobre todo porque la mayoría son interacciones normales, libres de toda sospecha. Los expertos hay que reservarlos para los casos difíciles.
Para solucionar ambos problemas existen los sistemas IDS/IPS (Intrusion Detection System / Intrusion Prevention System). Los IDS detectan los ataques y los IPS actúan contra ellos. Tenemos dos tipos de IDS/IPS:
- NIDS/NIPS (Network Intrusion Detection System y Network Prevention Detection System). Buscan ataques sobre servicios de comunicaciones. Se basan en el análisis de los paquetes que forman parte de la comunicación entre dos máquinas, comprobando que se ajustan al protocolo estándar.
- HIDS/HIPS (Host Intrusion Detection System y Host Prevention Detection System). Buscan ataques sobre las aplicaciones y el sistema operativo de la máquina. Se basan en el análisis de los procesos actuales (ocupación de CPU y memoria, puertos abiertos, etc.) y la configuración y el log de cada uno de los servicios.
La inteligencia de estas herramientas suele residir en un conjunto de reglas que se cargan en el programa desde un fichero de configuración. Las reglas son elaboradas por expertos en seguridad que, cuando han identificado un nuevo tipo de ataque, escriben la regla que permitirá al IDS detectarlo.
Los problemas de los IDS son dos:
- Rendimiento. El número de reglas es creciente (hay nuevos ataques y no podemos descartar los antiguos) y el volumen de tráfico también, por lo que necesitamos un hardware muy potente para tener funcionando un IDS sobre capturas de tráfico en tiempo real. En determinados momentos, la cola de paquetes pendientes de examinar será tan larga que la interfaz estará a punto de empezar a descartarlos; para evitarlo, el IDS los dejará pasar, a sabiendas de que puede ser un ataque (si no los deja pasar, nosotros mismos estaremos ejecutando un ataque). Pero si nos limitamos a procesar ficheros de captura antiguos, puede que encontremos ataques que ya han ocurrido y sea tarde para reaccionar.
- Falsos positivos. Las reglas no son perfectas y puede que estemos alertando sobre comunicaciones que son perfectamente legales. Conviene probar muy bien una regla antes de meterla en un IPS.
Preguntas sobre el vídeo:
- ¿Qué significan las siglas IDS?
- ¿Qué significan las siglas IPS?
- ¿Qué es mejor un IDS o un IPS a nivel de seguridad?
- ¿Es un IDS un sistema pasivo o activo? ¿Y un IPS?
- ¿Dónde se deberia poner un IDS o un IPS?
- ¿Qué es un UTM?
¿Qué es Snort?
¿Qué es el INCIBE?
Leer el artículo ¿Qué es un IDS?.
¿Qué significan las siglas IDS?
¿Es un IDS un firewall?
En el contexto de un IDS ¿Qué es un falso positivo?
En el contexto de un IDS ¿Qué es un falso negativo?
Firewall
Hemos visto que la tarea de los NIPS es dura: revisar todos los paquetes que transitan por la red buscando patrones de ataques conocidos. Los consiguientes problemas de rendimiento impiden que muchas empresas los utilicen. Pero si efectivamente conocemos las características del ataque (puerto donde intenta conectar, tipo de dirección IP origen inválida, tamaño del paquete utilizado), otra forma de defensa es tomar medidas en las máquinas que tengamos bajo nuestro control para que reaccionen adecuadamente ante la presencia de estos paquetes sospechosos. Es decir, los paquetes que consigan entrar en nuestra red, engañar al NIPS (si lo tenemos) y llegar a nuestros equipos, o que intentan salir procedentes de una aplicación no autorizada (por ejemplo, un troyano nos puede convertir en generadores de correo spam), todavía tienen que superar un control más en cada equipo: el firewall o cortafuegos. La seguridad es como un conjunto de láminas de queso gruyere unas al lado de otras.
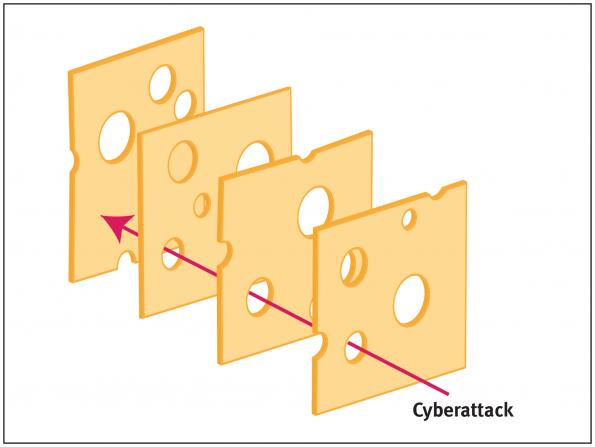 Seguridad por capas
Seguridad por capas
Preguntas sobre el video:
- ¿Existen los firewall hardware?
- ¿Qué es un firewall?
- ¿Sabrías poner un ejemplo de un firewall físico en la vida real?
- ¿Dónde se pone el firewall firewall?
- ¿Un firewall nos puede proteger de nuestra propia red?
- ¿Cuantos tipos de firewall nos comenta Alberto Lopez TECH TIPS? 4
¿Qué hace un firewall?
El firewall es un software especializado que se interpone entre las aplicaciones y el software de red para hacer un filtrado de paquetes:
- En el tráfico entrante, la tarjeta de red recibe el paquete y lo identifica, pero antes de entregarlo a la aplicación correspondiente, pasa por el firewall para que decida si prospera o no. En el ejemplo del servidor web, la máquina recibe un paquete destinado al puerto 80, pero antes de entregarlo al proceso que tiene abierto ese puerto (un apache.exe), el firewall decide.
- En el tráfico saliente, las aplicaciones elaboran sus paquetes de datos, pero antes de entregarlo al software de red para que lo envíe, pasa por el firewall. Por ejemplo, si sospechamos que una máquina hace spam, podemos bloquear todas las conexiones salientes al puerto 25.
¿Donde se sitúa un firewall?
Todas las máquinas de la empresa conectadas a la red necesitan activar un firewall. Incluso aunque no ejecuten ningún servidor: Puede que el software de red del sistema operativo tenga una vulnerabilidad. Igual que el malware hay que bloquearlo con el antivirus porque es software no solicitado, el firewall nos ayuda a bloquear paquetes de red no solicitados.
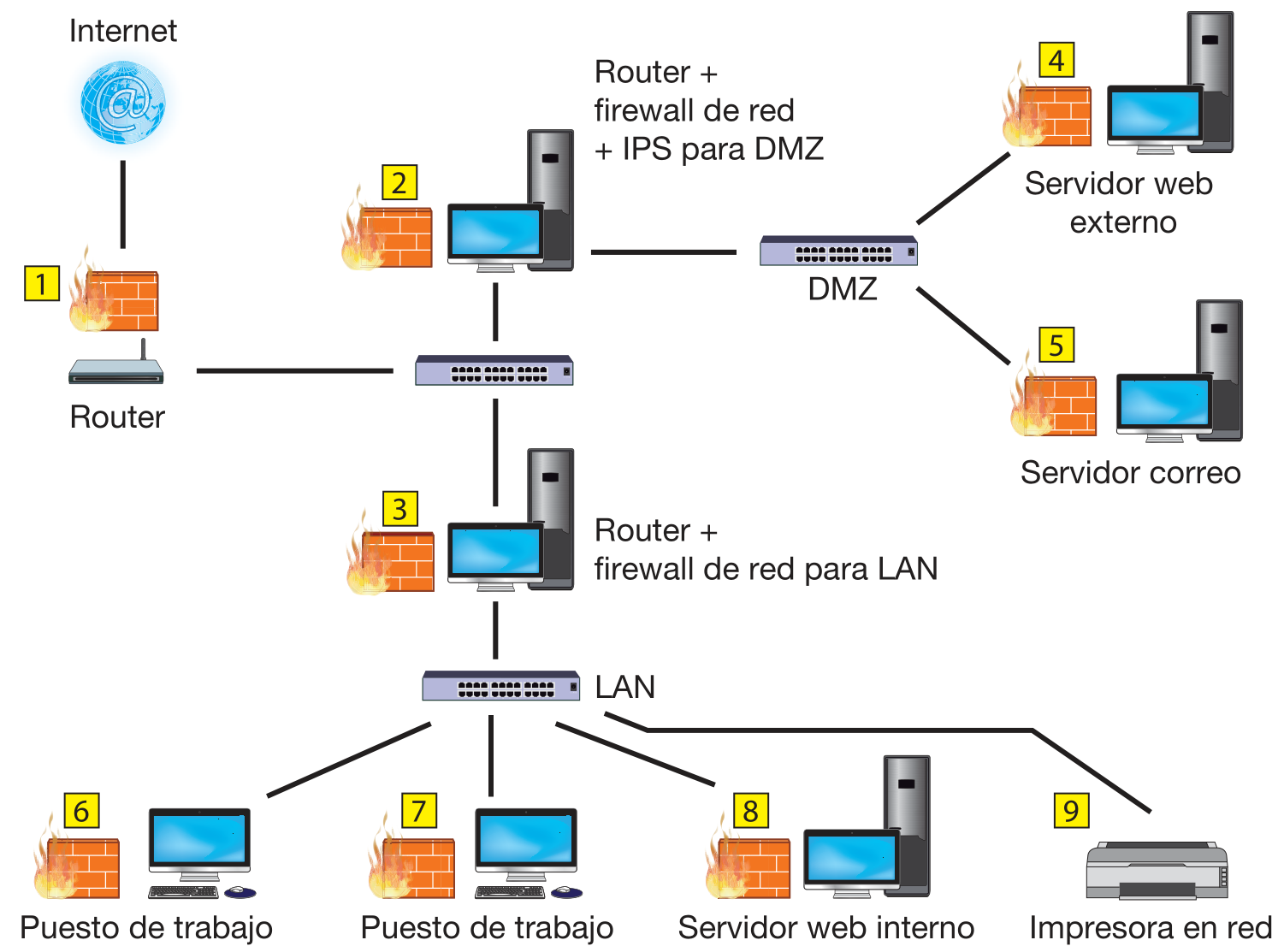 Despliegue completo de firewall en la empresa
Despliegue completo de firewall en la empresa
Firewall en GNU Linux
Cuando llega un paquete a la tarjeta de red, el sistema operativo (más concretamente, el software de red) decide qué hacer con él. El resultado de esa decisión puede ser:
- Descartarlo. Si el destinatario del paquete no es nuestra máquina o, aunque lo sea, ningún proceso actual lo espera, el paquete termina aquí. Por ejemplo, llega una petición http a una máquina que no tiene un servidor web arrancado: la máquina lo ignora.
- Aceptarlo, porque es para nosotros y hay un proceso que sabe qué hacer con ese paquete.
- Aceptarlo, aunque no sea para nosotros, porque somos un router y vamos a enviarlo por otra interfaz. En algunos casos llegaremos a modificar las cabeceras del paquete, como veremos más adelante.
- Aceptarlo, aunque no es para nosotros y tampoco somos un router: pero estamos escuchando todos los paquetes porque somos un sniffer de red.
En el caso de Linux, la utilidad iptables permite introducir reglas en cada una de estas fases:
- Cuando llega el paquete para un proceso nuestro pero todavía no se lo hemos entregado, en iptables hablamos de input.
- Cuando somos un router y estamos a punto de traspasar el paquete de una interfaz a otra, en iptables hablamos de forward.
- Cuando un paquete está listo para salir por una interfaz, en iptables hablamos de output.
Hay un par de etapas más:
- Prerouting. Se ejecuta antes de input. Sirve para obviar el enrutamiento porque sabemos exactamente qué tratamiento dar a esos paquetes.
- Postrouting (después de output y después de forward). Se utiliza para aplicar alguna modificación a los paquetes que están a punto de abandonar la máquina.
Las reglas de iptables tienen una lista de condiciones y una acción, de manera que, cuando un paquete cumple todas las condiciones de una regla, se ejecuta la acción. En las condiciones podemos utilizar la interfaz por la que entró, la interfaz por la que va a salir, la dirección IP o la subred del paquete, el tipo de protocolo, el puerto origen o destino, etc. Las acciones pueden ser simplemente aceptar o rechazar el paquete, o también modificarlo.
Pero no todas las acciones están disponibles en todas las situaciones. Por esto las reglas se agrupan en tres tablas principales:
- filter. Es la tabla principal. Su misión es aceptar o rechazar paquetes. Es el firewall propiamente dicho.
- nat. Las reglas de esta tabla permiten cambiar la dirección de origen o destino de los paquetes.
- mangle. En esta tabla podemos alterar varios campos de la cabecera IP, como el ToS (Type of Service). Se suele usar para aplicar QoS (Quality of Service), marcando los paquetes de determinados servicios para luego priorizarlos.
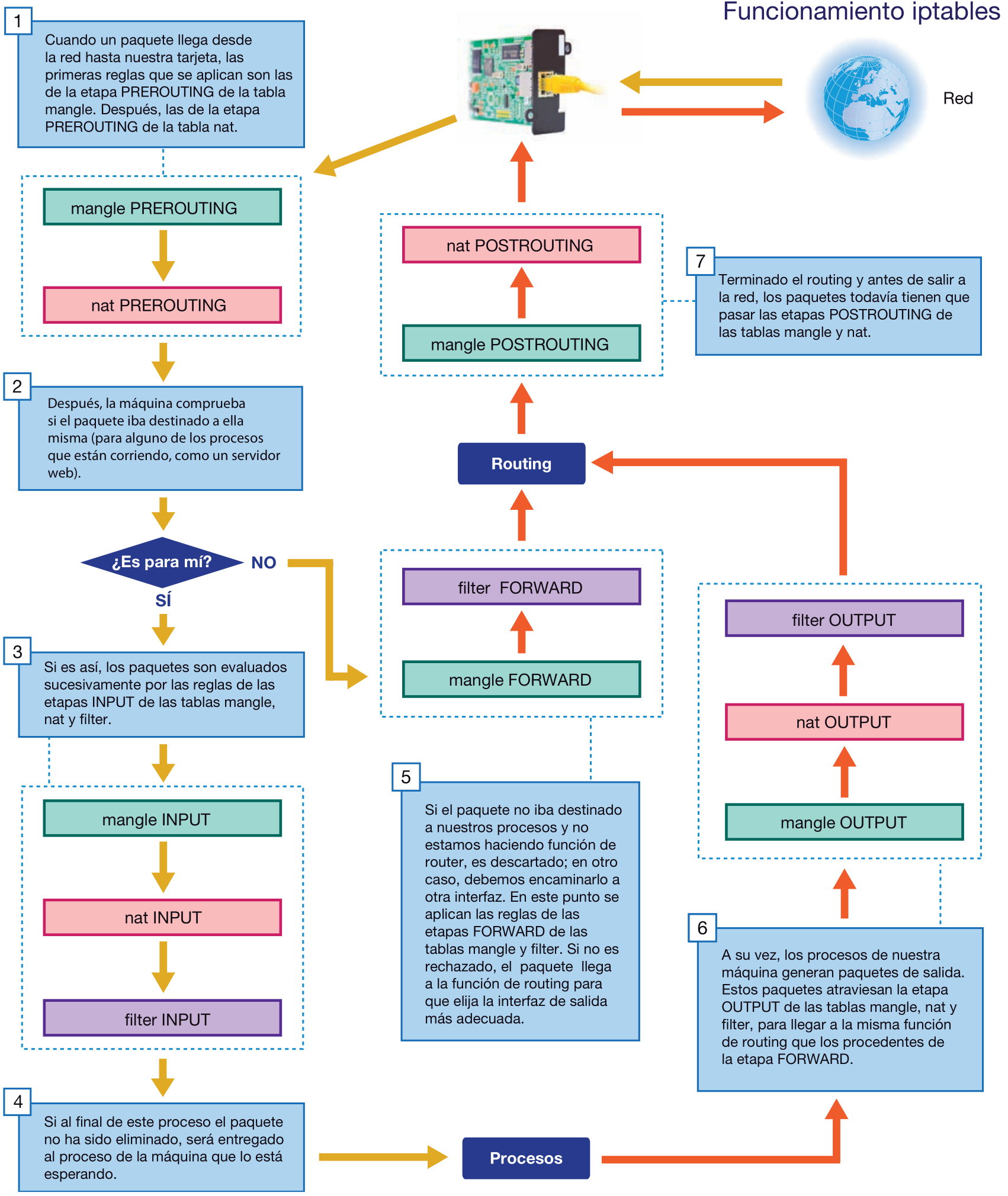 Esquema iptables
Esquema iptables
¿Qué significa ToS? ¿Qué significa QoS?
¿Qué es un UTM?
Leer el artículo UTM, un firewall que ha ido al gimnasio.
- ¿Qué significan las siglas UTM?
- ¿Tiene sentido poner un UTM si ya tenemos un IDS en nuestra red?
- ¿Tiene sentido poner un UTM si ya tenemos un IPS en nuestra red?
- ¿Tiene sentido poner un IDS o IPS si ya tenemos un UTM en nuestra red perimetral?
- ¿Es un UTM un firewall?
Proxy
¿Qué diferencias hay entre un proxy y una VPN (Virtual Private Network)?
Un proxy es un servicio de red que hace de intermediario en un determinado protocolo. El proxy más habitual es el proxy HTTP: Un navegador en una máquina cliente que quiere descargarse una página web de un servidor no lo hace directamente, sino que le pide a un proxy que lo haga por él. El servidor no se ve afectado porque le da igual quién consulta sus páginas.
No hay que ver siempre la seguridad como algo negativo porque nos impide navegar por algunas webs; también puede impedir que entremos en determinados sitios peligrosos donde podemos recibir un ataque. Además, en las empresas hay otros motivos para instalar un proxy:
- Seguridad para el software del cliente. Puede ocurrir que el software del ordenador cliente esté hecho para una versión antigua del protocolo o tenga vulnerabilidades. Pasando por un proxy actualizado evitamos estos problemas.
- Rendimiento. Si en una LAN varios equipos acceden a la misma página, haciendo que pasen por el proxy podemos conseguir que la conexión al servidor se haga solo la primera vez, y el resto recibe una copia de la página que ha sido almacenada por el proxy.
- Anonimato. En determinados países hay censura a las comunicaciones, por lo que utilizar un proxy del les permite navegar con libertad.
- Acceso restringido. Si en nuestra LAN no está activado el routing a Internet, sino que solo puede salir un equipo, podemos dar navegación al resto instalando un proxy en ese equipo.
¿Qué hace un proxy?
El proxy recibe de una máquina origen A un mensaje formateado para el servidor B según un protocolo determinado. Lo procesa y genera un nuevo mensaje para el mismo destino B, pero ahora el origen es P, la máquina del proxy (petición 2). Cuando el servidor B genera la respuesta, la envía a P (respuesta 3). La máquina P procesa ese mensaje y genera su propio mensaje de respuesta con destino A (respuesta 4).
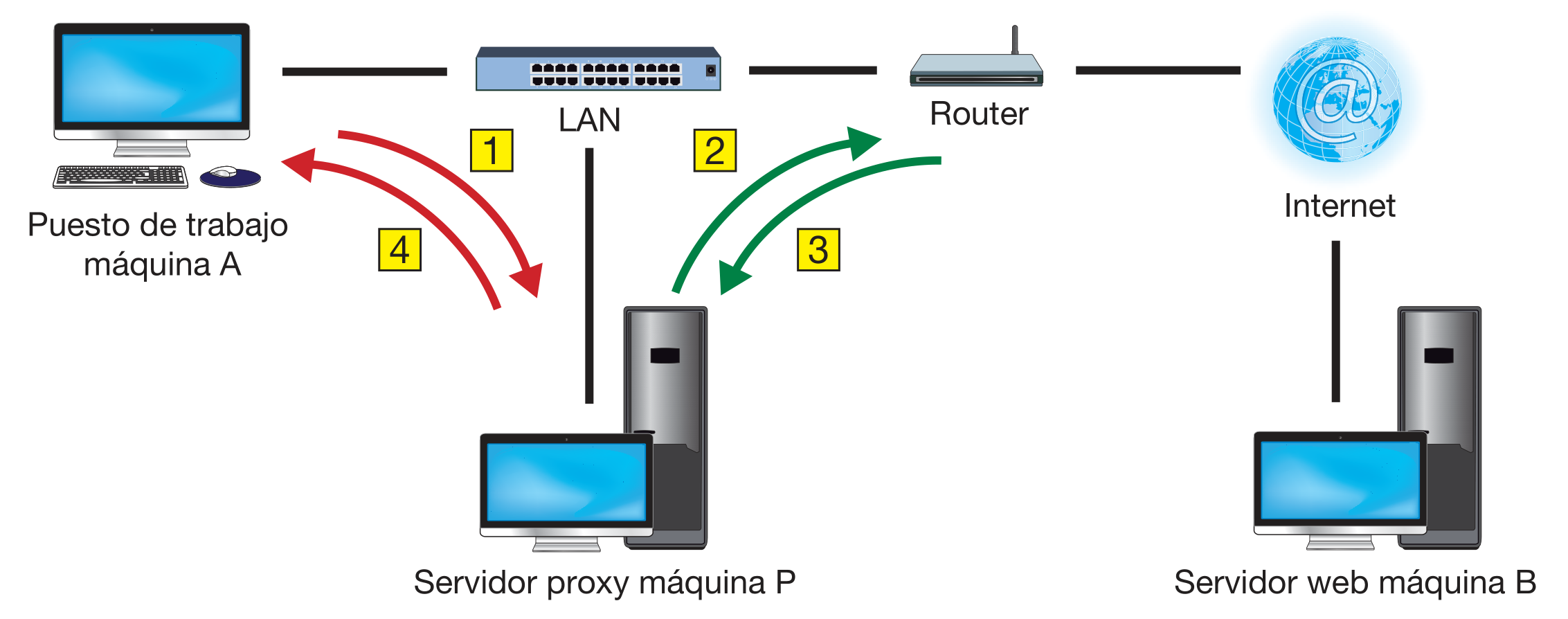 Funcionamiento de un proxy HTTP
Funcionamiento de un proxy HTTP
Además de controlar las conexiones web, el proxy mejora el rendimiento global de la navegación porque guarda en disco las páginas que envía a los clientes. Es el llamado proxy caché. De esta manera, si esa misma máquina o cualquier otra solicita al proxy la misma página (le envía la misma petición 1), no hace falta generar la petición 2 ni esperar la respuesta 3: directamente, el proxy le devuelve la respuesta 4. Hemos ahorrado los dos mensajes que van sobre la red más lenta.
¿Donde se sitúa un proxy?
Si el volumen de tráfico que pasará por el proxy es reducido y las reglas definidas son sencillas, el servidor proxy necesitará pocos recursos (CPU, RAM, disco para la caché), por lo cual puede estar incluido en una máquina que ya ofrezca otros servicios (DHCP, DNS, disco en red, correo).
Si el volumen es elevado o las reglas que hemos definido son complejas, no podemos permitirnos afectar a otros servicios: Necesitaremos una máquina en exclusividad (incluso más de una, formando un clúster). Aunque habrá que dimensionar adecuadamente el ancho de banda en esas máquinas dedicadas, porque van a recibir mucho tráfico.
Tipos De Proxy
Si instalamos un proxy para un determinado protocolo (por ejemplo, HTTP), el siguiente paso es conseguir que el tráfico de nuestros usuarios pase por ese proxy. Tenemos dos opciones:
- Proxy explícito. Configuramos los navegadores de los usuarios para que utilicen el proxy de la empresa.
- Proxy transparente. En algún punto de la red un router filtrará ese tipo de tráfico (por ejemplo, comprobando que el destino es el puerto 80 de TCP) y lo enviará al proxy, sin que el usuario tenga que hacer nada. Si estamos utilizando un router Linux, la solución óptima es instalarlo ahí, porque ahorramos sacar el tráfico hasta otra máquina.
Una tercera opción de navegación proxy al alcance de los usuarios es utilizar un proxy web. Esto es, una página web donde entramos para introducir la URL de la página web que realmente queremos visitar. El servidor del proxy web conecta con esa página y nos muestra el resultado. Este mecanismo es el más utilizado para evitar la censura en algunos países. En una empresa no es aceptable porque el tráfico de nuestros empleados está pasando por la máquina de una empresa desconocida y no sabemos qué puede hacer con esos datos.
¿Qué es un proxy transparente?
¿Es rápido configurar un proxy explícito en una LAN?
¿Qué es un proxy inverso? ¿Para qué se utiliza?
¿Qué es Proxy Squid?
El software de servidor proxy más extendido es Squid. Tiene versión para Windows, pero aquí veremos la versión GNU Linux, que es la más utilizada.
Spam
En las empresas, el correo electrónico es tan importante o más que el teléfono. Los empleados necesitan estar en contacto con otros empleados de la misma empresa, con los proveedores y con los clientes. Como responsables de la infraestructura informática, debemos garantizar que los mensajes se envían y reciben con normalidad, pero también que no hacemos perder el tiempo a nuestros usuarios entregando correos no deseados (spam). Estos correos, como mínimo, llevan publicidad, pero también son una fuente de infección de virus y troyanos que pueden venir en un fichero adjunto o que aprovechan una vulnerabilidad del programa de correo.
¿Que es el spam?
¿Qué hace el software antispam?
El software antispam colabora con el servidor de correo para detectar mensajes indeseables. Para determinar si un mensaje entra en esa categoría, el antispam utiliza:
- La cabecera del mensaje, buscando si el servidor de correo origen está en alguna lista negra de spammers reconocidos, si la fecha de envío utiliza un formato incorrecto (sugiere que el correo ha sido generado por un software de spam, no por un cliente de correo normal), etc.
- El contenido del mensaje, buscando palabras poco relacionadas con la actividad de la empresa (medicinas, etc.), mensajes cuya versión de texto plano es muy diferente de la versión HTML (sugiere de nuevo que ha sido generado con un programa de spam), etc.
- La propia experiencia del programa (autoaprendizaje), según el tipo de mensajes que maneja el servidor de correo de nuestra empresa en concreto.
Cuando se detecta un correo spam, tenemos varias opciones:
- Bloquearlo aquí e impedir que llegue hasta el usuario; así le ahorramos molestias (leerlo, borrarlo) y evitamos potenciales infecciones. No se suele usar porque nunca tendremos la certeza de que no hemos eliminado algún correo importante.
- Dejarlo pasar, pero avisando al usuario de que es un correo sospechoso. Es la opción por defecto. El aviso al usuario consiste en añadir texto en el título del correo (por ejemplo, ** SPAM **); esto le servirá al usuario para crear sus propios filtros en su programa de correo.
- Dejarlo pasar, pero convirtiendo el texto del correo en un fichero adjunto, para que sea más difícil engañar al usuario y solo lo abra si está seguro de que el correo le interesa.
¿Qué es SpamAssasin?
El software SpamAssasin es uno de los software antispam más extendidos por su eficacia y la amplia variedad de filtros que puede llegar a aplicar para determinar si un correo es spam. Los filtros se especifican mediante reglas. Si un mensaje cumple una regla, se le asigna una puntuación. Cuando un mensaje supera un determinado umbral (por defecto, 5, aunque lo podemos cambiar), se considera que es spam.
SpamAssasin, además, utiliza técnicas de inteligencia artificial (redes neuronales) para reducir el número de falsos positivos (correo spam que no lo es) y falsos negativos (correo spam que no ha sido detectado como tal).