
1. Introducción
En este artículo se va a tratar la historia la web así como su funcionamiento básico.
2. Historia de Internet
Leer artículo Historia de Internet: cómo nació y cuál fue su evolución
¿Cómo se llamaba el primer satélite artificial lanzado al espacio?
¿En que se basa la teoría de conmutación de paquetes?
¿Qué unía la red ARPANET?
¿Que dos ciudades se unieron por primera vez?
¿Cuál es el país con mayor penetración de internet?
¿Cuál es el sitio web más visitado del mundo?
¿Cuál fue la primera red social de la historia?
Leer artículo Historia de Internet hasta la sección “Evolución de Internet en cifras” incluida.
Leer artículo Historia de internet hasta la sección “WWW” incluida.
3. Historia de la web
Ver hasta el año 2001…
¿Qué es una página web?
Una página web es un documento HTML. Este documento HTML es interpretado por un navegador:
- Google Chrome
- Mozilla Firefox
- Internet Explorer
- Microsoft Edge
- Opera
- Safari
¿Es lo mismo Internet que la web?
No. WEB = INTERNET + HTTP
4. La web 1.0
La web primitiva, la del siglo 20, era aquella que se caracteriza principalmente por ser unidireccional y realizada sobre contenidos estáticos. Las primeras páginas que vimos en Internet publicaban contenidos de texto que, una vez publicados, no se actualizaban salvo que el “webmaster” modificase dichos contenidos y volviese a subir la web de nuevo a internet.
La web 1.0 tenía un carácter principalmente divulgativo, y empezaron a colgarse de internet documentos e información principalmente cultural. Poco a poco las empresas empezaron a tomar parte y las primeras webs de empresa surgieron, con diseños muy pobres (no había herramientas, ni tecnología, ni conexión suficiente como para hacerlo mejor) y contenidos que rápidamente quedaban anticuados al ser complejo actualizarlos.
5. La web 2.0
La web 2.0 se asiento a mediados de la primera década de este siglo. Sustentada bajo unas conexiones a internet evolucionadas (ya teníamos ADSL), y mejores herramientas para desarrollar web, mejores servidores, etc., la web 2.0, también denominada “la red social”, llena Internet de blogs, wikis, foros y finalmente, redes sociales. El objetivo de la web 2.0 es la compartición del conocimiento, es la web colaborativa y ha sido uno de los atractivos principales para atraer a usuarios (basta ver los usuarios de facebook que, hasta facebook, no tocaban un ordenador).
¿La web de Homer Simpson es 1.0 o 2.0?
6. Web 3.0
La web 3.0 es:
- Web semántica
- Experiencia de navegación personalizada a través de:
- Analizar el historial de cada usuario
- Analizar datos de conducta web de cada usuario
- Desarrollar tecnologías 3.0 como la Inteligencia Artificial.
- Crear una base de datos global.
- Analizar la geolocalización del usuario.
- Etc.
Leer artículo ¿En qué consiste la web semántica?.
¿Qué diferencia existe entre la web semántica y sintáctica? ¿Sabrías poner un ejemplo?
¿Cuál fue el motivo del éxito de Google?
La respuesta del éxito actual de Google es sencilla: fue el primer buscador, como tal, que se tomó en serio su trabajo.
Google nació a finales de los años 90, como la tesis doctoral de Larry Page y Sergey Brin. En 1998 se estrenó en Internet y desde entonces se ha consagrado como el principal motor de búsqueda en el mundo.
Su principal innovación fue tener en cuenta la autoridad de las páginas, ganada a través de enlaces. Google desarrolló un sistema para cuantificar esta autoridad, y lo llamó “PageRank”.
Aunque hay que agregar que, a consecuencia de la gran importancia que Google otorgaba a los enlaces, muchos -si no es que todos- sitios web han estado creando enlaces no orgánicos durante años, consiguiendo más autoridad de la que correspondería de forma natural.
Por ello, y para intentar combatir este problema, las más reciente actualizaciones del algoritmo de Google se han centrado en otras métricas, como señales sociales, interacción del usuario y calidad de los contenidos, entre otras.
8. Arquitectura cliente-servidor
La web tiene una arquitectura cliente-servidor.
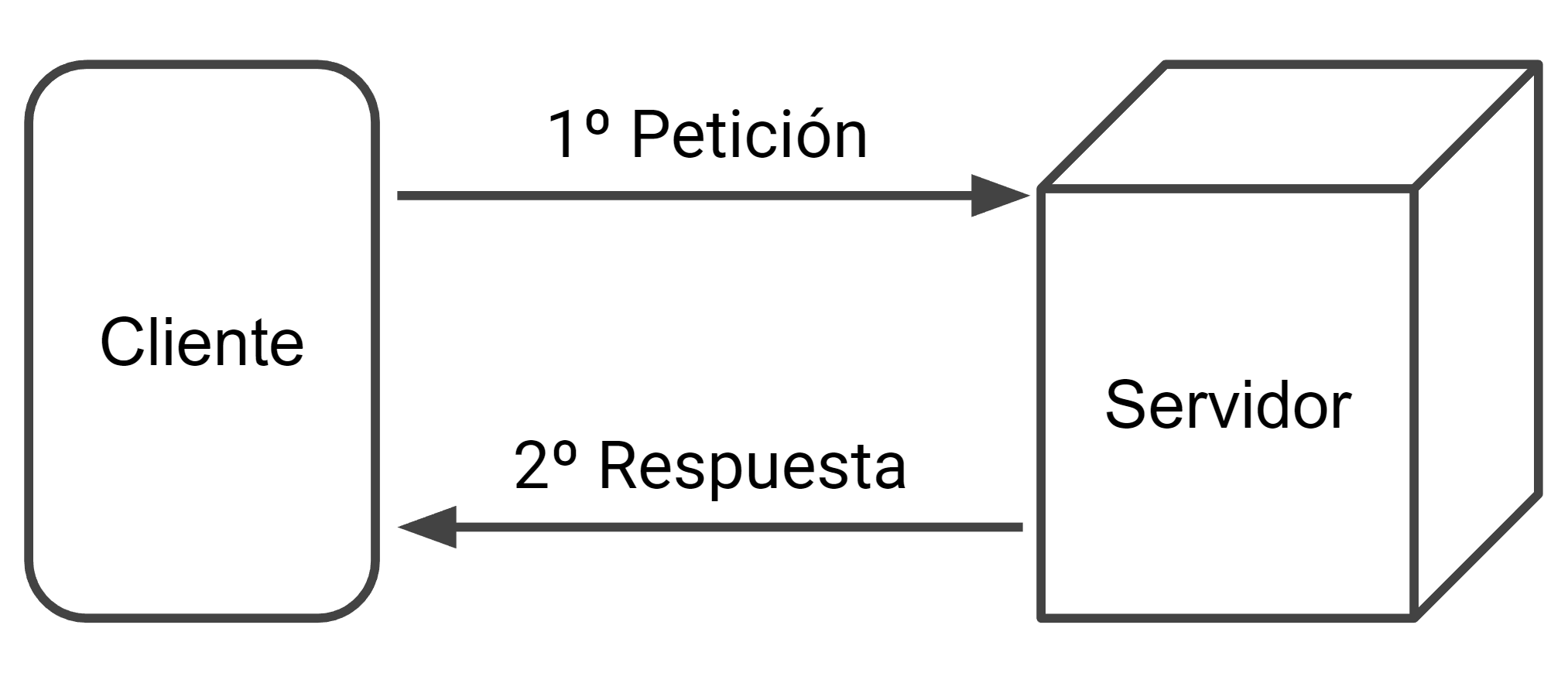 Arquitectura cliente-servidor
Arquitectura cliente-servidor
¿Qué diferencia hay entre una arquitectura cliente servidor y una arquitectura p2p?
Cliente-Servidor: es un modelo de aplicación distribuida en el que las tareas se reparten entre los proveedores de recursos o servicios, llamados servidores, y los demandantes, llamados clientes. Un cliente realiza peticiones a otro programa, el servidor, quien le da respuesta. Esta idea también se puede aplicar a programas que se ejecutan sobre una sola computadora, aunque es más ventajosa en un sistema operativo multiusuario distribuido a través de una red de computadoras.
P2P: es una red de computadoras en la que todos o algunos aspectos funcionan sin clientes ni servidores fijos, sino una serie de nodos que se comportan como iguales entre sí. Es decir, actúan simultáneamente como clientes y servidores respecto a los demás nodos de la red. Las redes P2P permiten el intercambio directo de información, en cualquier formato, entre los ordenadores interconectados.
Una de las diferencias, es que en el “CS” se necesita un servidor, y un cliente, a diferencia del “P2P”, que permite a cualquier usuario ser cliente o servidor. Una de las ventajas del “P2P” es que la conexión siempre estará activa, ya que con que haya un cliente, el servidor esta activo, pero en el “CS” se requiere que el servidor principal esté activo. En el “P2P” todo usuario o cliente tiene las mismas funciones que otro igual que él, aspecto contrario al “CS” en el cual un servidor tiene las funciones que los clientes no poseen.
¿Sabríais decirme 5 navegadores web?
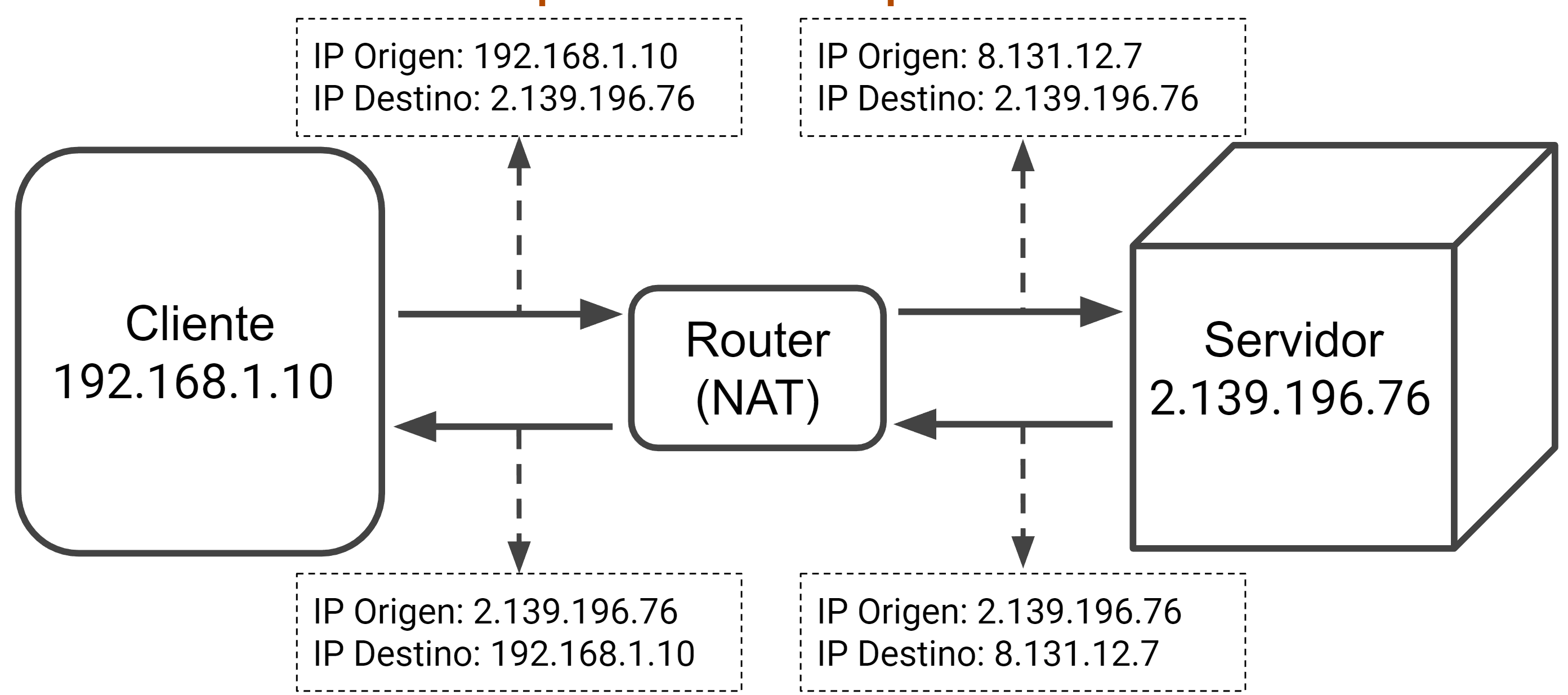 Arquitectura cliente-servidor con NAT
Arquitectura cliente-servidor con NAT
¿Qué significan las siglas NAT?
9. Direcciones de Internet
9.1. Direcciones IP
¿Cómo se llaman los proveedores de internet (siglas)?
¿Cómo puede Movistar disponer de menos IPs que usuarios?
¿Qué es la WAN?
¿Qué información tiene cada paquete TCP/IP?
Preguntas sobre el vídeo:
- ¿Cómo sabe el router a qué dispositivo de la LAN a la que va el paquete de respuesta?
- ¿El router analiza la dirección MAC para realizar el trabajo del NAT satisfactoriamente?
- ¿Qué es el NAT? ¿En qué dispositivo suele estar?
- ¿Cuál es la IP de la puerta de enlace?
- ¿Cuál es el rango de direcciones IP? ¿Cómo se puede calcular?
- ¿Es lo mismo la puerta enlace que el gateway? ¿Qué le(s) corresponde(n)?
- ¿Por qué existen las IPs privadas? ¿No podrían ser todas públicas y así ahorrarnos el paso de traducción?
9.2. URLs
Todo recurso de Internet debe tener una dirección accesible desde cualquier ordenador del mundo. A esa dirección se le llama URLs (Uniform Resource Locator).
Una URL es una secuencia de caracteres, de acuerdo a un formato estándar, que se usa para nombrar recursos en Internet para su localización o identificación.
Esta imagen https://upload.wikimedia.org/wikipedia/en/thumb/2/22/Heckert_GNU_white.svg/246px-Heckert_GNU_white.svg.png tiene una URL en Internet.
{kind=link}
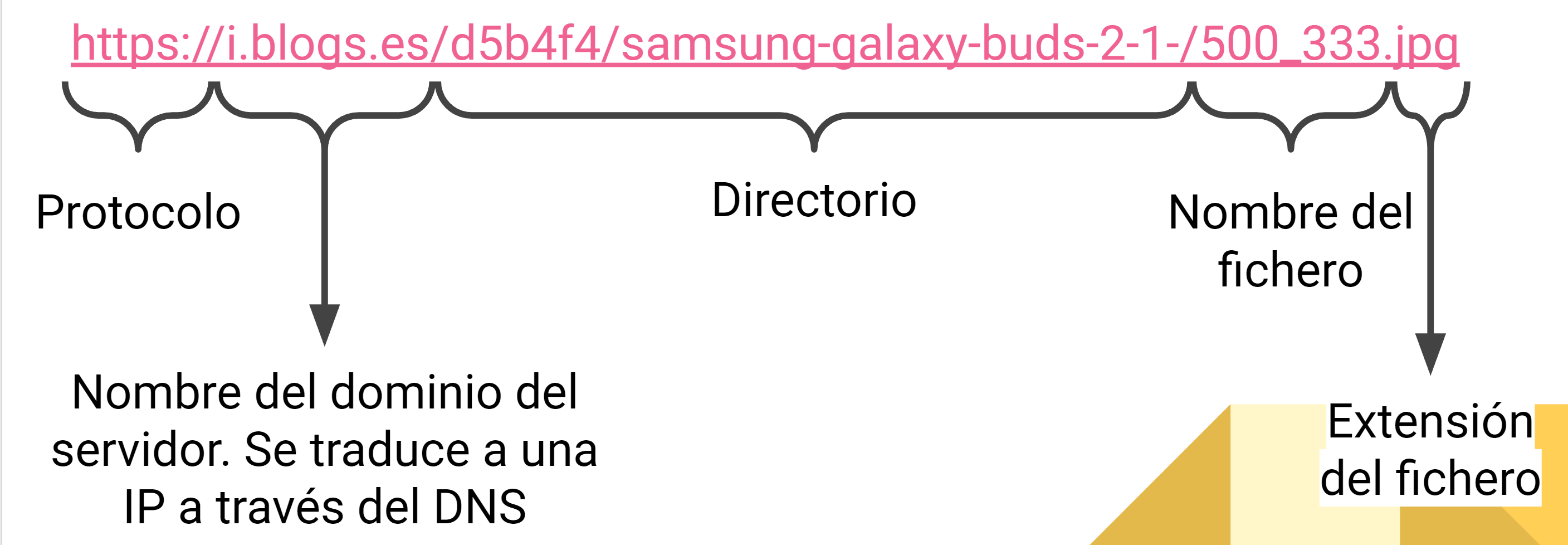 Formato de una URL
Formato de una URL
¿Por qué usamos dominios?
La IP del centro educativo IES Leonardo de Chabacier es 2.139.196.76. Cómo memorizar estos números es poco práctico se crearon los servidores DNS y así asociar estas IPs a nombres.
¿Qué es un DNS y para qué sirve?
Cada dispositivo conectado a Internet tiene una dirección IP única que otros equipos pueden usar para encontrarlo. Los servidores DNS (Domain Name System) suprimen la necesidad de que los humanos memoricen direcciones IP tales como 192.168.1.1 (en IPv4) o nuevas direcciones IP alfanuméricas más complejas, tales como 2400:cb00:2048:1:c629:d7a2 (en IPv6).
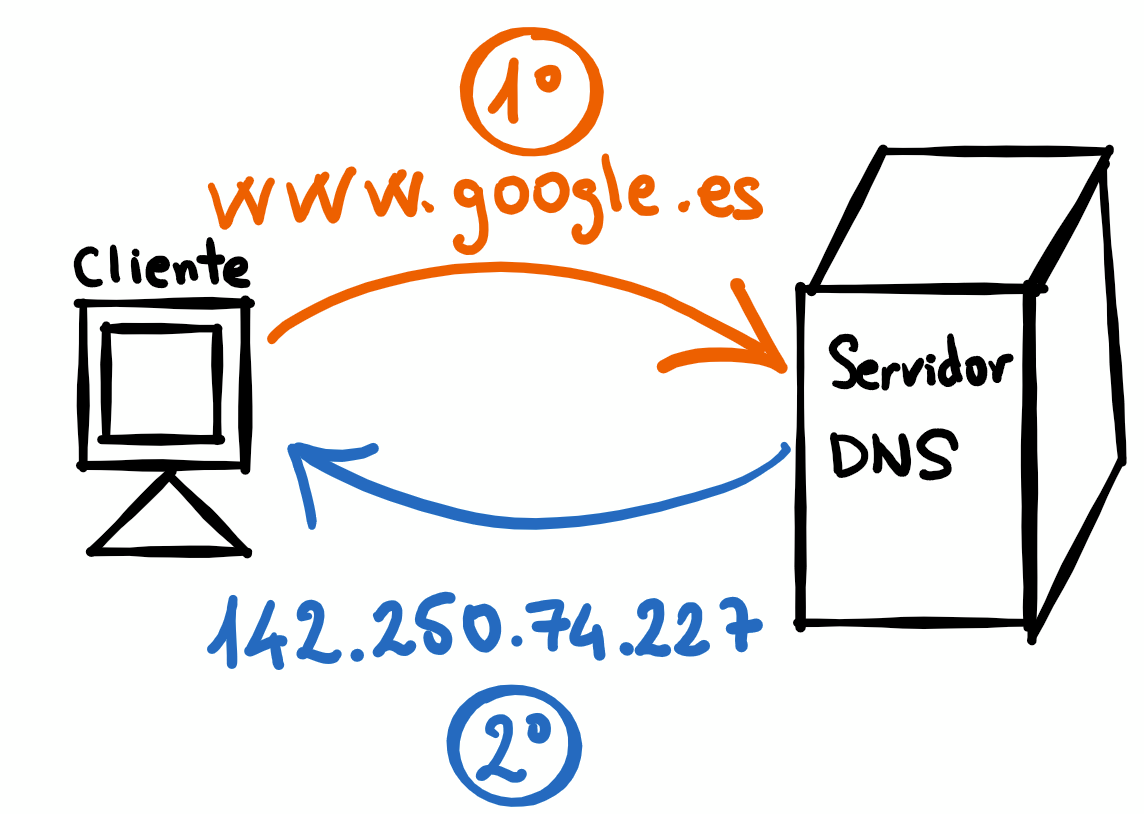 Comunicación cliente-servidor DNS básica
Comunicación cliente-servidor DNS básica
10. HTML
Leer artículo HTML.