
¿Qué es el Machine Learning?
El Machine Learning es una rama de la Inteligencia Artificial que se centra en el uso de datos y algoritmos para imitar el modo en que aprendemos los humanos gradualmente e incrementando la precisión sin intervención humana.
Tom Mitchell proporciona una definición moderna: “Se dice que un programa de computadora aprende de la experiencia E con respecto a alguna clase de tareas T y medida de desempeño D, si su desempeño en las tareas de T, medido por D, mejora con la experiencia E.”
Ejemplo de jugar a las damas:
- E = la experiencia de jugar muchos juegos de damas.
- T = la tarea de jugar a las damas.
- D = la probabilidad de que el programa gane el próximo juego.
Los modelos de aprendizaje automático se obtienen mediante el entrenamiento de los algoritmos con subconjuntos de datos. Ese subconjunto se denomina “training dataset” o conjunto de entrenamiento.
La esencia del machine learning comporta la existencia de un patrón que no podemos precisar matemáticamente a pesar de disponer de un gran volumen de datos (llamado dataset).
La década de 2000 marcó el comienzo de rápidos avances en el aprendizaje automático y el aprendizaje profundo, en parte debido a la ley de Moore y al auge de la informática en la nube. El resultado es un acceso más fácil a capacidades de informática y almacenamiento más grandes, más rápidas y económicas. Ahora puede alquilar potencia informática durante unas horas a un coste muy reducido, en comparación con las enormes inversiones necesarias para comprar y operar clústeres informáticos a gran escala.
- Inteligencia artificial (AI): Rama de la informática que intenta simular diferentes comportamientos humanos por parte de las máquinas.
- Aprendizaje automático (ML): Es una parte de la inteligencia artificial (pero no la única) que permite a las máquinas aprender a partir de los datos sin ser programadas. Se centra en el uso de datos para entrenar modelos de aprendizaje automático para que los modelos puedan hacer predicciones.
- Redes neuronales (NN): Uno de los tipos de aprendizaje automático (hoy en día, uno de los más populares). Es una técnica inspirada en la biología humana. Utiliza capas de neuronas para construir redes que resuelven problemas.
- Aprendizaje profundo (DL): Método para construir, entrenar y usar redes neuronales con múltiples capas internas.
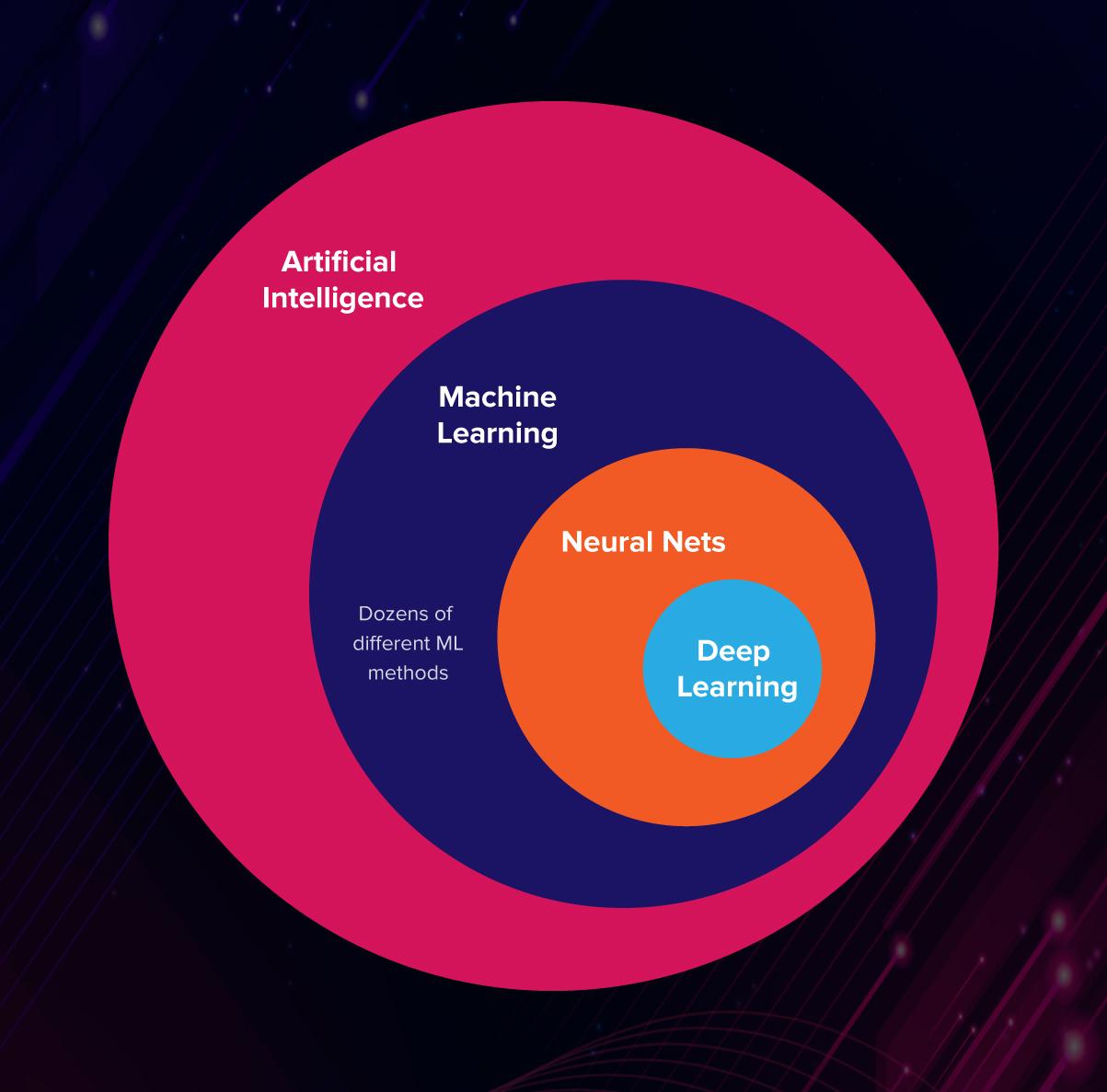 Aprendizaje automático vs aprendizaje profundo
Aprendizaje automático vs aprendizaje profundo
Vídeo resumen IA en inglés: https://www.youtube.com/watch?v=oV74Najm6Nc.
¿Qué es la ley de Moore?
¿Es lo mismo el aprendizaje automático que el machine learning?
Si.
¿Es lo mismo inteligencia artificial que el machine learning?
No.
Preguntas sobre el vídeo:
- ¿Qué dos tipos de IA existen?
- ¿Hay algún ejemplo de IA fuerte en la vida real?
- ¿Cuál es el término que se usa en inglés para “aprendizaje automático”?
- ¿Qué 3 paradigmas de aprendizaje automático existen?
- ¿Cuál es la diferencia entre el aprendizaje automático y la inteligencia artificial?
- ¿Por qué es necesario/útil el deep learning?
Preguntas sobre el vídeo:
- A día de hoy, ¿pueden las máquinas hacer una tarea específica mejor que las personas?
- ¿Cómo aprende el pequeño robot?
- ¿Qué es un modelo?
- ¿Cómo se llama en aprendizaje automático agrupar en grupos los datos de muestra?
- ¿En que se diferencia el aprendizaje supervisado del no supervisado?
- ¿Qué es el aprendizaje semisupervisado?
Preguntas sobre el vídeo:
- ¿Existen hoy en dia máquinas con autoconciencia?
- ¿Para qué sirven los captchas?
Componentes del machine learning
Los componentes del machine learning son:
- Entrada: x
- Salida: y
- Función destino: f: X→ Y
- Datos: (x1,y1),(x2,y2)…(xN,yN)
- Hipótesis: g:X→ Y
Si hacemos un paralelismo con un supuesto de solicitud de un crédito bancario, cada uno de los componentes se corresponderían con:
- x: solicitud del cliente con sus datos concretos
- y: resultado. Aprobación o denegación del crédito. ¿Es x un buen o mal cliente?
- Función f: fórmula ideal de aprobación de un crédito
- Data: registros históricos previos de los que disponemos
- Función g: fórmula generada que se utilizará para aprender
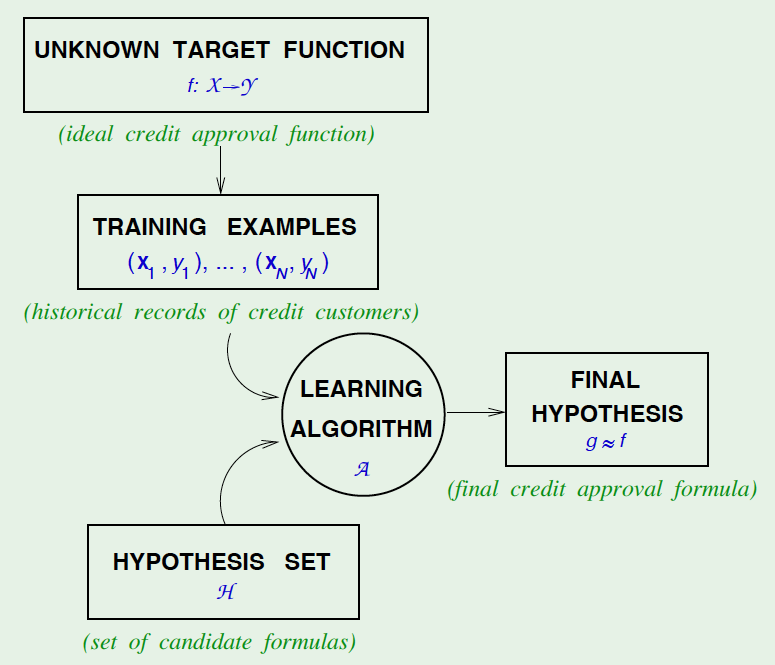 Componentes del machine learning
Componentes del machine learning
Los dos componentes que por tanto formarán parte de la solución serán:
- Conjunto de fórmulas candidatas de hipótesis (H)
- Algoritmo de aprendizaje (A)
Junto, ambos componentes serán referidos como el MODELO DE APRENDIZAJE.
Cuando los datos que se usan para entrenar el modelo representan con precisión el conjunto de datos completo que se va a analizar, el algoritmo obtiene patrones que relacionan las variables/características (o features). Los resultados se suelen denominar etiquetas.
Cuando el modelo de aprendizaje automático se ha entrenado para realizar su tarea de forma suficientemente rápida y precisa como para que sea útil y confiable se ha conseguido inteligencia artificial débil o estrecha.
Vídeo explicativo de los componentes del machine learning en inglés: https://www.youtube.com/watch?v=mbyG85GZ0PI.
Etapas del machine learning
- Para comenzar, siempre se debería comenzar identificando el problema empresarial que se cree que puede beneficiarse del aprendizaje automático.
- Después de formular el problema, pasa a la fase de preparación y preprocesamiento de datos. En esta fase, extraerá datos de uno o más orígenes de datos. Estos orígenes de datos pueden tener diferencias en datos o tipos que deben reconciliarse para formar una única vista cohesiva de los datos. Debe visualizar los datos y utilizar las estadísticas para determinar si los datos son consistentes y se pueden utilizar para el aprendizaje automático. En 2017, un estudio de O’Reilly presentó que los profesionales del aprendizaje automático dedican el 80% de su tiempo a trabajar en esta fase.
- Después de preparar los datos y garantizar su exactitud y consistencia, es hora de entrenar el modelo. En esta etapa, el proceso se vuelve iterativo y fluido. Es probable que se tarden varias iteraciones de diseño, entrenamiento, evaluación y ajuste de las características antes de encontrar un modelo que pueda cumplir con los objetivos de negocio. El proceso iterativo puede dividirse en tres grandes pasos:
- Procesamiento de datos: El diseño de las características es el proceso de selección o creación de las características que se utilizará para entrenar el modelo. Las características (features) son las columnas de datos que tiene dentro del conjunto de datos. El objetivo del modelo es intentar estimar correctamente el valor objetivo para los nuevos datos. El algoritmo de aprendizaje automático utiliza las características para predecir el destino.
- Entrenamiento de modelos: Después de limpiar los datos e identificar sus características, es hora de entrenar un modelo. No se utilizan todos los datos para entrenar el modelo. En su lugar, debe retener algunos datos para que pueda tener algunos datos con los que probar. Normalmente, se utiliza alrededor del 80% de los datos para entrenar, y se guarda el resto para realizar los testeos.
- Evaluación de modelos: con el modelo entrenado, puede usar algunos de los datos de prueba para ver qué tan bien funciona el modelo. Puede tomar una instancia que el modelo desconozca y utilizarla para realizar una predicción. Debido a que ya conoce el objetivo en los datos de prueba, puede comparar los dos valores. A partir de estas comparaciones, puede calcular métricas, que le proporcionan datos sobre el rendimiento del modelo. A continuación, modificará los datos, las características o los hiperparámetros del modelo hasta que encuentre el modelo que obtenga los mejores resultados.
- Después de volver a entrenar el modelo y estar satisfecho con los resultados, se implementa el modelo para ofrecer las mejores predicciones posibles.
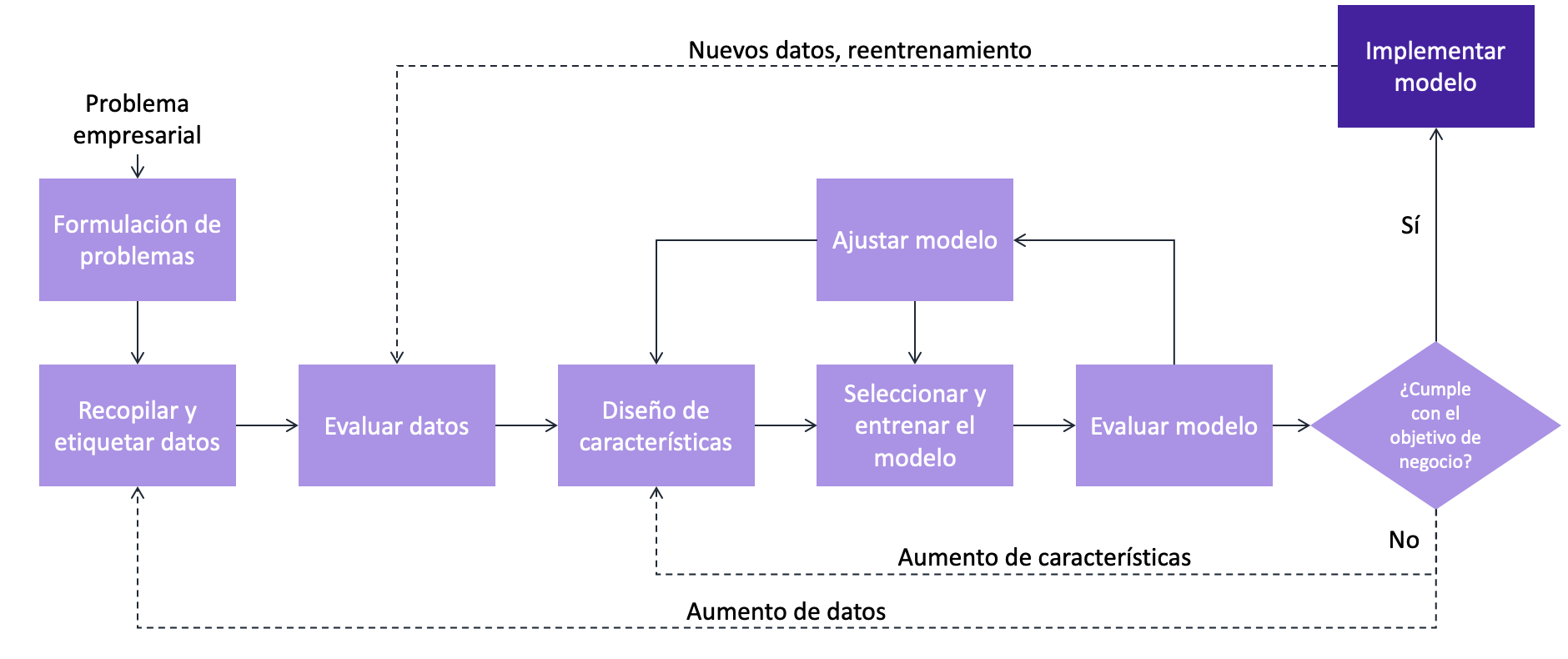 Etapas del machine learning
Etapas del machine learning
Ejemplos de machine learning
Estos son algunos ejemplos del machine learning:
- Spam: Su filtro de spam es el resultado de un programa de aprendizaje automático al que se entrenó con ejemplos de spam y mensajes de correo electrónico normales.
- Recomendaciones: En función de los libros que lea o de los productos que compre, los programas de aprendizaje automático predicen otros libros o productos que podrían gustarle. Una vez más, el programa de aprendizaje automático se entrenó con datos de hábitos y compras de otros lectores.
- Fraude de tarjetas de crédito: Del mismo modo, el programa de aprendizaje automático se entrenó con ejemplos de transacciones que resultaron ser fraudulentas, junto con transacciones que eran legítimas.
- Aprobación de créditos bancarios.
- Predicción de precios.
Existen muchos más ejemplos, que incluyen la detección facial en aplicaciones de redes sociales para agrupar fotos, la detección de tumores cerebrales en escáneres cerebrales o la búsqueda de anomalías en los rayos X.
Eso sí, no todos los problemas deben resolverse con el aprendizaje automático, y a veces la programación básica funciona igual de bien. Cuando explore una posible solución de aprendizaje automático, busque elementos como la existencia de grandes conjuntos de datos y un gran número de variables. También es posible que no esté seguro de la lógica de negocio o de los procedimientos necesarios para obtener una respuesta o realizar una tarea. En tales casos, el aprendizaje automático suele ser la mejor opción.
Los sistemas de aprendizaje automático pueden ser complejos. La infraestructura de apoyo, el apoyo a la administración y la experiencia deben estar en su lugar para ayudar al proyecto a tener éxito.
TRES tipos de machine learning
El machine learning se clasifica en TRES tipos de aprendizaje: por refuerzo, supervisado y no supervisado.
- En el aprendizaje supervisado, cada muestra de entrenamiento del conjunto de datos tiene una etiqueta correspondiente o un valor de salida asociado. Como resultado, el algoritmo aprende a predecir etiquetas o valores de salida.
- En el aprendizaje no supervisado, no hay etiquetas para los datos de entrenamiento. Un algoritmo de aprendizaje automático intenta aprender los patrones o distribuciones subyacentes que gobiernan los datos.
- En el aprendizaje por refuerzo, el algoritmo determina qué acciones tomar en una situación para maximizar una recompensa (en forma de número) en el camino hacia la consecución de un objetivo específico. Este es un enfoque completamente diferente al aprendizaje supervisado y no supervisado.
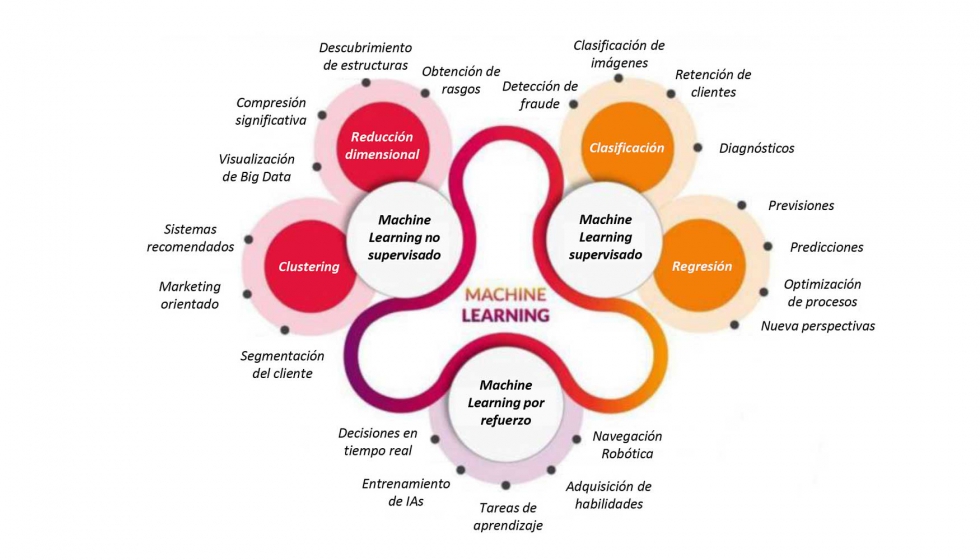 Tipos de machine learning
Tipos de machine learning
A continuación veremos cada uno de ellos.
Aprendizaje supervisado
Leer artículo Aprendizaje Supervisado.
Aprendizaje no supervisado
Leer artículo Aprendizaje No Supervisado.
Aprendizaje por refuerzo
Es un aprendizaje que une al supervisado y no supervisado.
El aprendizaje por refuerzo consiste en la iteración constante y basada en “prueba y error”. Una computadora es capaz de realizar iteraciones ante determinadas condiciones y con un objetivo específico llamado “recompensa”, ya que el algoritmo de aprendizaje recibe una valoración sobre la relevancia de la respuesta dada. Si la respuesta es correcta, el aprendizaje por refuerzo actúa como el aprendizaje supervisado.
El objetivo del aprendizaje por refuerzo consiste, por tanto, en maximizar la recompensa acumulativa total, así que con el tiempo, el agente aprende, a través de prueba y error, a identificar aquellas acciones que incrementan dicha recompensa. Cuanto mejor entrenado esté el agente, más eficientemente elegirá aquellas acciones que logren su objetivo.
El aprendizaje por refuerzo es particularmente útil para abordar problemas secuenciales con objetivos a largo plazo.
Este tipo de aprendizaje es el más habitual en la naturaleza. A diferencia de éste, el aprendizaje supervisado informa exactamente al algoritmo de que hubiese tenido que responder en caso de responder erróneamente.
Ejemplos:
- RL es excelente para jugar a juegos:
- Go (juego de mesa) fue dominado por el software AlphaGo Zero de DeepMind (filial de Google) sucesor de Alpha Zero.
- Los videojuegos clásicos de Atari se utilizan comúnmente como una herramienta de aprendizaje para crear y probar software RL.
- StarCraft II, el videojuego de estrategia en tiempo real, fue dominado por el software AlphaStar.
- RL se utiliza en el diseño de niveles de videojuegos:
- El diseño de nivel de videojuego determina qué tan compleja es cada etapa de un juego y afecta directamente a qué tan aburrido, frustrante o divertido es jugar ese juego.
- Las empresas de videojuegos crean un agente que juega el juego una y otra vez para recopilar datos que se pueden visualizar en gráficos.
- Estos datos visuales brindan a los diseñadores una forma rápida de evaluar qué tan fácil o difícil es para un jugador progresar, lo que les permite encontrar el equilibrio “perfecto” entre el aburrimiento y la frustración de forma más rápida.
- RL se utiliza en la optimización de la energía eólica:
- Los modelos RL también se pueden utilizar para impulsar la robótica en dispositivos físicos.
- Cuando varias turbinas trabajan juntas en un parque eólico, las turbinas en el frente, que reciben el viento primero, pueden causar malas condiciones de viento para las turbinas detrás de ellas. Esto se llama estela turbulenta y reduce la cantidad de energía que se captura y se convierte en energía eléctrica.
- Las organizaciones de energía eólica de todo el mundo utilizan el aprendizaje por refuerzo para probar soluciones. Sus modelos responden a las condiciones cambiantes del viento cambiando el ángulo de las palas de la turbina. Cuando las turbinas delanteras disminuyen, ayuda a las turbinas traseras a capturar más energía.
- Otros ejemplos de RL del mundo real incluyen:
- Robótica industrial.
- Detección de fraudes.
- Análisis de la bolsa.
- Conducción autónoma.
Preguntas
¿Qué es un conjunto de entrenamiento etiquetado y en qué tipo de machine learning se utiliza?
¿Cuáles son las dos tareas supervisadas más comunes?
¿Qué tipo de algoritmo de machine learning utilizarías para permitir a un robot caminar por varios terrenos desconocidos?
Aprendizaje por refuerzo.
¿Qué tipo de algoritmo de machine learning utilizarías para segmentar a tus clientes en múltiples grupos?
Aprendizaje no supervisado - clustering.
¿Definirías el problema de detección de spam como un problema de aprendizaje supervisado o no supervisado?
Aprendizaje supervisado - clasificación (spam vs. no spam).
¿Porqué es útil separar los datos en entrenamiento y prueba?
¿Para qué se utiliza la función de activación de un perceptrón?
Activar(1)/inhibir(0) el paso de información desde la neurona actual a la neurona de la siguiente capa.
Tenemos un conjunto de datos de personas con los campos edad, sexo, peso, altura y el índice de masa corporal. Si queremos entrenar una red neuronal para hacer una predicción de este último parámetro (índice de masa temporal) en función del resto, ¿cuántas neuronas tendrá nuestra red neuronal en la capa de entrada? ¿Y cuántas neuronas tendrá la capa de salida?
4 de entrada y 1 de salida.
¿Cuántas neuronas hacen falta en la capa de salida para clasificar mails entre correo no deseado y correo deseado?
¿Qué tipo de red neuronal utilizarías para crear un traductor de texto?
RNN o transformadora.
¿Para qué se utiliza la ecuación de Bellman? Busca un ejemplo que justifique su uso.
En aprendizaje por refuerzo para reducir y optimizar los cálculos de las recompensas. Por ejemplo: ajedrez, control de ingeniería.